反復処理:すべてのタスクを同時に実行
Difyを使用した多言語ドキュメント翻訳ツールの構築
⬇️ 読む前に、試してみてください
はじめに
急速に進化するAIアプリケーション開発の分野では、ローコードプラットフォームが企業のインテリジェントソリューション実装方法を革命的に変えています。Difyは変革的なオープンソースプラットフォームとして登場し、最小限のコーディング努力でAI駆動のワークフローを構築、展開、スケーリングすることをチームに可能にします。そのモジュラーアーキテクチャと視覚的なワークフローデザインにより、ドキュメント処理から多言語コラボレーションまで、インフラストラクチャの複雑さを抽象化しながらAI機能のシームレスな統合を実現します。
この記事では、DeepSeek R1とオープンソースのローコード開発プラットフォームDifyを組み合わせて、企業レベルの多言語ドキュメント翻訳ツールを迅速に構築する方法を示します。Difyのシームレスな統合により、ユーザーは複雑なプログラミングなしでドキュメントの解析、スタイリスティックな翻訳、バッチ処理を自動化でき、言語間コラボレーションの効率を大幅に向上させます。技術マニュアルの正確な翻訳であれ、多言語マーケティングコンテンツの柔軟な適応であれ、このソリューションはモジュラーワークフローを通じて簡単に実装でき、グローバルチームにコスト効率が高く、高度に制御可能なAIソリューションを提供します。
Backend as a Service:Difyローコードを使用したAIアプリケーションバックエンドの構築
前提条件
-
DeepSeek APIキーを申請する。
-
Difyアカウントに登録する。
DeepSeek APIキーの申請
方法1:DeepSeek APIオープンプラットフォーム経由
DeepSeek APIオープンプラットフォームにアクセスし、画面上の指示に従ってAPIキーを申請します。
Difyへの登録
Difyは生成AIアプリケーションを迅速に構築するのに役立つプラットフォームです。DeepSeek APIと統合することで、使いやすいDeepSeek AIアプリケーションを迅速に作成できます。
DeepSeekをDifyに接続する
Difyプラットフォームにアクセスし、右上のアバターをクリック → 設定 → モデルプロバイダーを選択し、DeepSeekを見つけて、先ほど取得したAPIキーを貼り付けます。

保存をクリックします。検証が成功すると、成功メッセージが表示されます。
アプリケーションの作成
Studioに入り、ブランク → ワークフローから作成をクリックします。
チャットフローとワークフローとは? Difyの高度なアプリケーションタイプには、チャットフローとワークフローがあります。チャットフローはよりチャットボットのように動作します。つまり、ユーザーとループで対話できるロボットです。一方、ワークフローはよりスクリプトのように動作し、呼び出されるときに一度だけ実行され、通常はアプリケーションバックエンドとして使用されます。 構築しているアプリケーションシナリオに応じて、適切なアプリケーションタイプを選択する必要があります。このデモでは、ワークフロータイプを選択します。

ワークフローの構築
アプリケーションに入ると、ノードを追加して接続することでワークフローを編集できます。コードを処理する必要はありません。
以下では、ドキュメント翻訳ツールの作成方法を示します:
スタートノード
スタートノードで、+をクリックしてファイルタイプの変数を追加します。ファイルタイプをファイルリストとして選択し、ファイルタイプをドキュメントに設定し、変数名を「file」とします。

また、翻訳スタイルを制限する必要があります。例:フォーマル、プロフェッショナル、カジュアル、熱意のある、ユーモラス。+をクリックしてオプションタイプの変数を追加し、各オプションの内容を入力し、変数名をstyleに設定します。

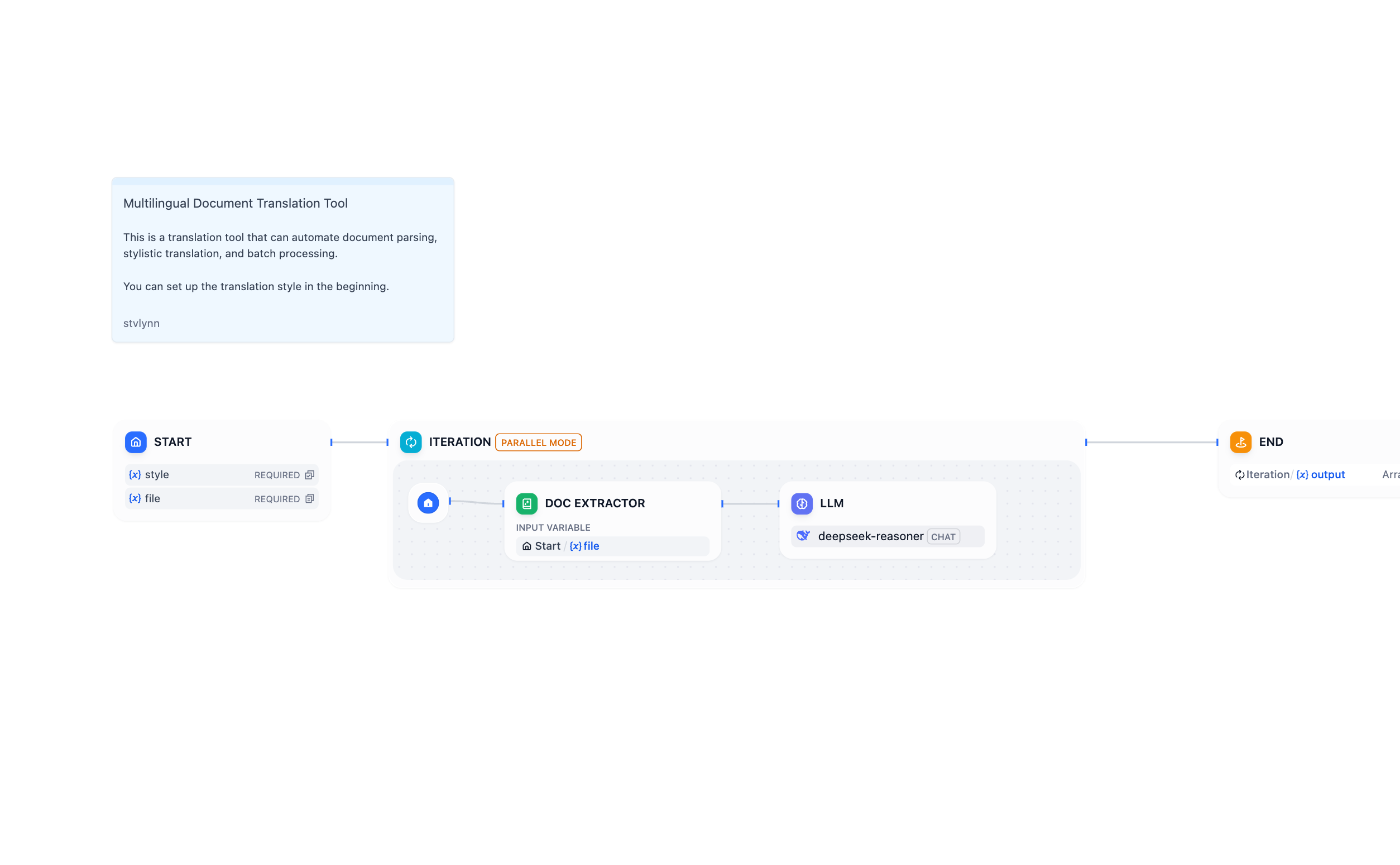
反復処理
スタートノードでは、ファイルのリストを設定しました。ワークフローノードを繰り返し構築することを避けるために、Difyは反復ノードを導入しています。反復ノードでは、ワークフローはリストタイプの変数をすべて完全に実行し、個別に出力します。
反復の詳細な説明については、ドキュメンテーション -> 反復を参照してください。

以下では、反復ノード内のワークフローをさらに設定します:
まず、スタートノードの後に反復ノードを追加します。反復ノードは小さなワークフローのようなもので、スタート変数と出力変数もあることがわかります。ここでは、反復ノードの入力変数をfileに設定する必要があります。

次に、反復ノード内にノードを追加します。LLMはアップロードされたドキュメントの内容を直接読み取ることができないため、ドキュメント抽出器を追加して、ドキュメントコンテンツをLLMが読み取れるテキストに変換する必要があります。ドキュメント抽出器の入力変数は、スタートノードのファイルファイルです。
ドキュメント抽出器の後に、LLMノードを追加し、システムプロンプトとユーザー入力を設定します。
以下はシステムプロンプトです:
システムプロンプトでは、/または{を入力して変数を挿入できます。
公式DeepSeekは、すべてのユーザーが参照できるプロンプトライブラリを提供しています。
最初からLLMアプリケーションを構築する場合、Difyはより包括的で使いやすいテンプレートも提供しています。エクスプローラページを開き、必要なテンプレートを閲覧してスタジオに取り込み、編集することができます。

最後に、反復ノードをクリックし、出力変数をLLMの出力に設定します。

テストと公開
公開する前に、サービスが適切に機能していることを確認するためにテストを実行できます。
**「実行」をクリックし、すべての変数を入力し、「実行開始」**をクリックして実行を開始します。


テストが合格したら、**「公開」**をクリックしてアプリケーションをオンラインデプロイします。デプロイリンクを友人と共有して一緒にテストすることができます。

アプリケーションのフロントエンドインターフェースをさらに開発したい場合は、DifyのAPIドキュメントを参照できます。右側の**「APIアクセス」**をクリックして、APIドキュメントを表示し、アプリケーションのAPIキーを管理します。

パフォーマンスの最適化
テストでは、特にDeepSeek R1のような推論モデルを使用する場合、ドキュメントの翻訳速度が遅いことがわかるかもしれません。速度を最大化するために、ワークフロー内の反復を改善する必要があります。
反復ノードを選択し、並列モードをオンにして、合理的な並列タスク数を設定します。

並列モードを有効にすると、ワークフローはすべてのタスクを順次ではなく同時に実行します。これにより効率が大幅に向上します。

テンプレートの取得
自分でワークフローを構築するのが難しい場合は、エクスプローラページのDeepSeek列から直接テンプレートを取得するか、以下のリンクをコピーして、空白アプリケーションを作成するときに**「DSLからインポート」**を選択してURLを入力することができます。